The rise of Physical AI: world models, robotics, and the new legal frontier
Introduction
While some anticipate the bursting of an artificial intelligence bubble in 2026, a deeper and more structural shift is already underway: the rise of Physical AI and embodied robotics.
Much of the conversation around the digital revolution has focused on how humans engage with digital environments, and recent attention has largely centered on large language models. What is now emerging is a complementary trajectory. The future is not only one in which humans interact online or immerse themselves in virtual spaces, but one in which AI systems enter and operate within our physical world.
The frontier of AI is no longer confined to cognition. It is increasingly shaped by systems that perceive their environment, make decisions in uncertain conditions, and act alongside us, gradually reshaping how physical spaces, from industrial sites to homes and public environments, are organized and experienced.
Robotics provides a visible illustration of this evolution, whether in humanoid or non-humanoid forms, as seen in recent developments by Agility Robotics, Tesla, and Figure AI. These systems go beyond generating text or images. They are designed to move through complex environments, manipulate objects with dexterity, and operate in close proximity to humans. This requires continuous simulation of their surroundings, anticipation of possible outcomes, and real-time adjustment of behavior.
In this context, the key question is no longer whether these systems will scale, but whether organizations are prepared to design, deploy, and govern them in a controlled and responsible manner.

This article explores the rise of Physical AI through three complementary perspectives. First, it examines the technical shift from language-based systems to action-oriented models, focusing on world models as internal simulators that enable agents to perceive, anticipate, and interact with their environment. Second, it analyzes the transformation of training data, moving beyond text toward multimodal, synthetic, and spatial datasets that capture the structure and dynamics of the physical world. Finally, it addresses the legal implications of this evolution, highlighting the convergence of software and machinery regulation and the resulting challenges for designing, deploying, and governing embodied AI systems.
Part I – From language to action : world models as simulators of reality
Generative AI has demonstrated remarkable capabilities, but it reaches limits when physical interaction is required. A language model can describe how to pick up a glass, but it cannot reliably predict the consequences of doing so in a real environment. As emphasized by Yann LeCun, reasoning about the world requires perceiving and modeling it.
Physical AI aim to address this gap, notably through world models. A world model is an internal representation of the environment that allows an agent to simulate possible futures and evaluate actions before executing them.
Where a language model predicts the next token, a world model predicts how the state of the environment evolves given an action. In practice, this involves:
- learning spatial and physical representations,
- modeling dynamics over time,
- and in some cases enabling planning through internal simulation.
This capability is what could allow a robot to anticipate that an object may slip, that a human may move unpredictably, or that a path may become obstructed. Architectures such as Joint Embedding Predictive Architectures (JEPA) contribute to this shift by learning predictive representations in latent space without reconstructing raw data.
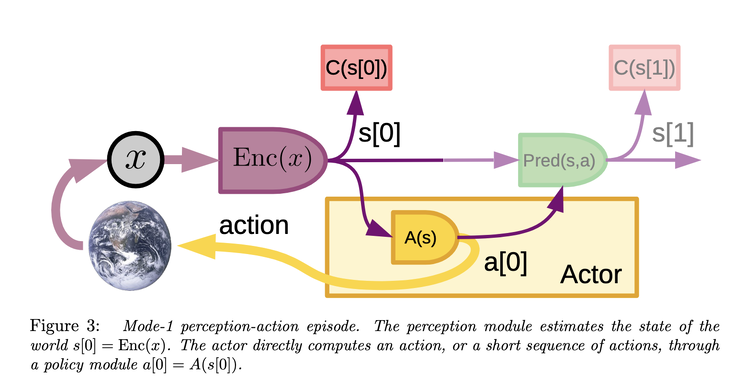
It is important to distinguish between representation learning and full environment modeling. JEPA focuses on learning useful predictive embeddings. A complete world model includes additional components such as dynamics modeling and planning mechanisms. This integration creates a feedback loop between real-world data and simulated environments. It also introduces new dependencies on the quality and legality of both real and synthetic data.
Part II – The shift of training dataset : towards multimodal, synthetic and spatial data
Physical AI systems depend on data that captures how the world looks, moves, and behaves:
- video data at scale,
- sensor data such as LiDAR or depth,
- geospatial data,
- telemetry data,
- simulation and synthetic data,
- 3D representations including point clouds and meshes

Nvidia provides a strong illustration of this evolution, particularly through platforms such as Omniverse and GR00T. These systems enable the generation of synthetic environments, the simulation of agent behavior, and the production of training data tailored to specific physical tasks.
These datasets are qualitatively different than text. A 3D scan for instance may encode spatial relationships, object affordances, and potentially identifiable personal or proprietary information.
Let’s consider a concrete scenario. A robotics company collects indoor scans to train navigation systems. These scans include furniture layouts, artworks, and personal objects. Even if individuals are not directly identifiable, the environment itself may reveal sensitive information. The dataset becomes legally complex even before training begins. A key question emerges: Does capturing a physical environment amount to reproducing it in a legal sense?
Consider another scenario. A fleet of mobile robots continuously records urban environments to improve navigation. The data includes pedestrians, storefronts, and private interiors visible from the street. The analogy between ‘world scraping’ and web scraping is intuitive, but legally uncertain. Web scraping extracts pre-existing digital content. Physical data capture actively reconstructs the environment through sensors, generating new representations such as point clouds or meshes.
Synthetic data will play a central role in Physical AI, but it covers different realities:
- physics-based simulation environments,
- generative outputs (e.g. diffusion models),
- reconstructed environments (e.g. NeRFs, Gaussian splatting).
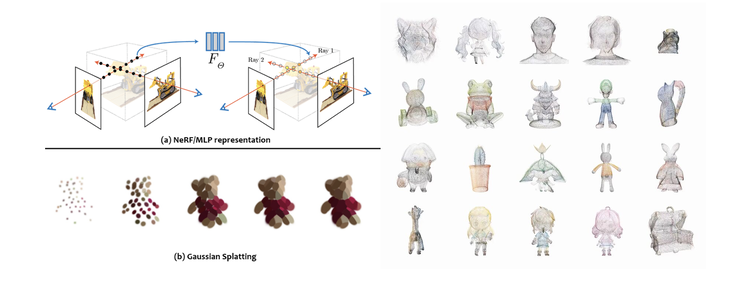
These categories differ in their legal implications. Simulation data may be entirely proprietary, generative data may raise questions related to derivative works, and reconstructed data may incorporate elements of real-world protected content.
This raises lots of legal questions for anyone interested in ‘physical data’.
- At what point can synthetic data be considered anonymized, and when does it remain personal data under the GDPR?
- Can a 3D reconstruction of a real environment, for example using NeRF techniques, constitute a reproduction of a protected work under copyright law?
- To what extent do rights attached to original datasets extend to synthetic data derived from them, particularly in generative or reconstruction contexts?
- And who, in practice, holds rights over synthetic datasets: the model developer, the operator generating the data, or the provider of the underlying sources?
- Under which circumstances, would a stakeholder have rights over a digital replica?
These questions are compounded by operational considerations. What level of documentation and traceability is required to explain how synthetic data was generated and used in training? Does large-scale capture and reconstruction of real-world environments introduce legal obligations that differ from traditional data collection methods?
Treating synthetic data as a single category, especially by Supervisory Authority, risks obscuring these distinctions and mischaracterizing both technical and legal risks. In practice, the origin, method of generation, and intended use of data directly affect not only compliance, but also system performance and liability exposure. As Physical AI systems increasingly rely on large-scale representations of real-world environments, these issues are likely to move from theoretical debate to concrete sources of regulatory scrutiny and litigation.
Part III – Legal layers applicable to Physical AI : a convergence of software and machinery regulation
Physical AI systems do not fall within a single regulatory category. They sit at the intersection of multiple legal regimes that were not designed to operate together in this way. What makes them particularly challenging is not only the number of applicable frameworks, but the fact that these frameworks overlap across both software and hardware layers, and across the entire lifecycle of the system.
A more accurate view of the regulatory landscape must therefore include both digital and industrial regimes:
- Data protection and privacy (e.g. General Data Protection Regulation; ePrivacy Directive)
- AI system regulation (e.g. AI Act)
- Product safety and liability (e.g. General Product Safety Regulation; Product Liability Directive)
- Machinery and industrial equipment regulation (e.g. Machinery Regulation, replacing Directive 2006/42/EC)
- Cybersecurity and system integrity (e.g. Cyber Resilience Act; NIS2 Directive)
- Intellectual property (e.g. Copyright in the Digital Single Market Directive; Database Directive)
- Contractual allocation of responsibility across the value chain (e.g. governed by national contract law, but also informed by EU instruments such as the Data Act).
These layers do not apply sequentially. They apply simultaneously, and often inconsistently, to the same system. Many use cases will be concerned. To start with, products and services combining sensors, AI, and robotics to assist humans, monitor infrastructure, detect anomalies, and support predictive maintenance. This ranges from domestic robots operating in everyday environments, to robotic arms in industrial settings, to autonomous inspection robots deployed in high-risk infrastructures.

One of the defining features of Physical AI is that it brings together two historically separate regulatory worlds: software regulation and machinery regulation.
- On the hardware side, robots are subject to industrial safety frameworks such as the EU Machinery Regulation. These frameworks are based on predictability, and pre-defined use cases. A machine must behave within known parameters, and risks must be mitigated at the design stage.
- On the software side, AI systems regulated under the AI Act are inherently risk-basis. Their behavior may evolve over time depending on the specific use case. Under the AI Act, many Physical AI systems are likely to qualify as high-risk (re Annex I or Annex III), particularly when used in workplaces, critical infrastructure, or as safety components.
A potential challenge lies in the alignment of legal definitions. A system could qualify as an “AI system” under the very large definition provided by article 3 of the EU AI Act without necessarily meeting the criteria of “AI-based machinery” under Annex I of the Machinery Regulation, which place greater emphasis on adaptive or self-evolving behavior. Systems relying on fixed vs learning algorithms might be captured by AI regulation but treated differently under machinery frameworks. In such cases, it is likely that both regimes will need to be considered together, raising questions about how their respective requirements should be articulated and combined in practice.
Besides, Physical AI systems process personal data continuously, often in uncontrolled environments. Unlike traditional IT systems, they do not rely on discrete data collection events but on ongoing perception.Under the GDPR, several challenges emerge simultaneously:
- identifying a valid legal basis for continuous data capture,
- ensuring proportionality in environments where data collection is ambient,
- managing secondary uses of data for training and improvement.
The attribution of liability might also becomes particularly complex when multiple actors (the manufacturer, the simulation provider, the integrator, the operator, etc.) contribute to system behavior. Liability may arise from design defects, software defects, or data-related deficiencies
Physical AI systems raise a set of interrelated regulatory questions that do not fit neatly within existing legal categories. How should compliance be assessed when a single system simultaneously qualifies as a machine, an AI system, and a data-processing infrastructure? At what point does a software update or model retraining constitute a substantial modification, potentially triggering a new conformity assessment or CE marking? And how can compliance be maintained over time when system behavior may evolve after deployment? These questions illustrate a broader challenge: applying regulatory frameworks designed for stable, well-defined systems to technologies that are adaptive, interconnected, and continuously changing.
In industrial deployment, manufacturers may therefore need to consider defining, from the outset, the scope of acceptable changes in system behavior, including updates to models, retraining processes, or parameter adjustments. This could involve documenting not only the intended use of the system, but also its expected range of adaptation, in order to help distinguish between controlled evolution and modifications that might alter the system’s risk profile.
For deployers and operators, this concept may introduce corresponding considerations at the operational level. In parallel, contractual arrangements across the value chain are likely to play an important role. Operators may depend on manufacturers or model providers to access technical documentation, logs, or evaluation tools necessary to assess compliance. As a result, contracts may increasingly need to anticipate these scenarios by clarifying responsibilities, facilitating access to relevant information, and setting out cooperation mechanisms in situations where a modification could trigger renewed regulatory obligations.
For regulators, the challenge lies in coordinating frameworks that were not designed to operate together. For companies, risk now extends across the entire lifecycle of the system. At the legal level, established approaches to responsibility, compliance, and risk distribution must be reconsidered.
#AI #worldmodel #JEPA #PhysicalAI #Robotics #Synthetic #Data #Regulation #Robots
------
My name is Adrien Basdevant, I am a Tech Lawyer specializing in AI, Data, Intellectual Property, and Digital Regulation. My work is dedicated to empowering inspiring entrepreneurs and innovative decision-makers by guiding them through complex regulatory landscapes.
As the co-founder of Entropy, a boutique EU law firm focused on emerging technologies, I lead a team committed to providing strategic legal and regulatory support for companies, from high-growth startups to established market leaders.
I work at the intersection of Law, Tech, and Policy. I advise on regulatory, compliance, product, contract negotiation, and litigation. Core Focus Areas: machine learning, encryption, content-sharing platforms, disruptive technologies, and digital rights.